The Core Insight
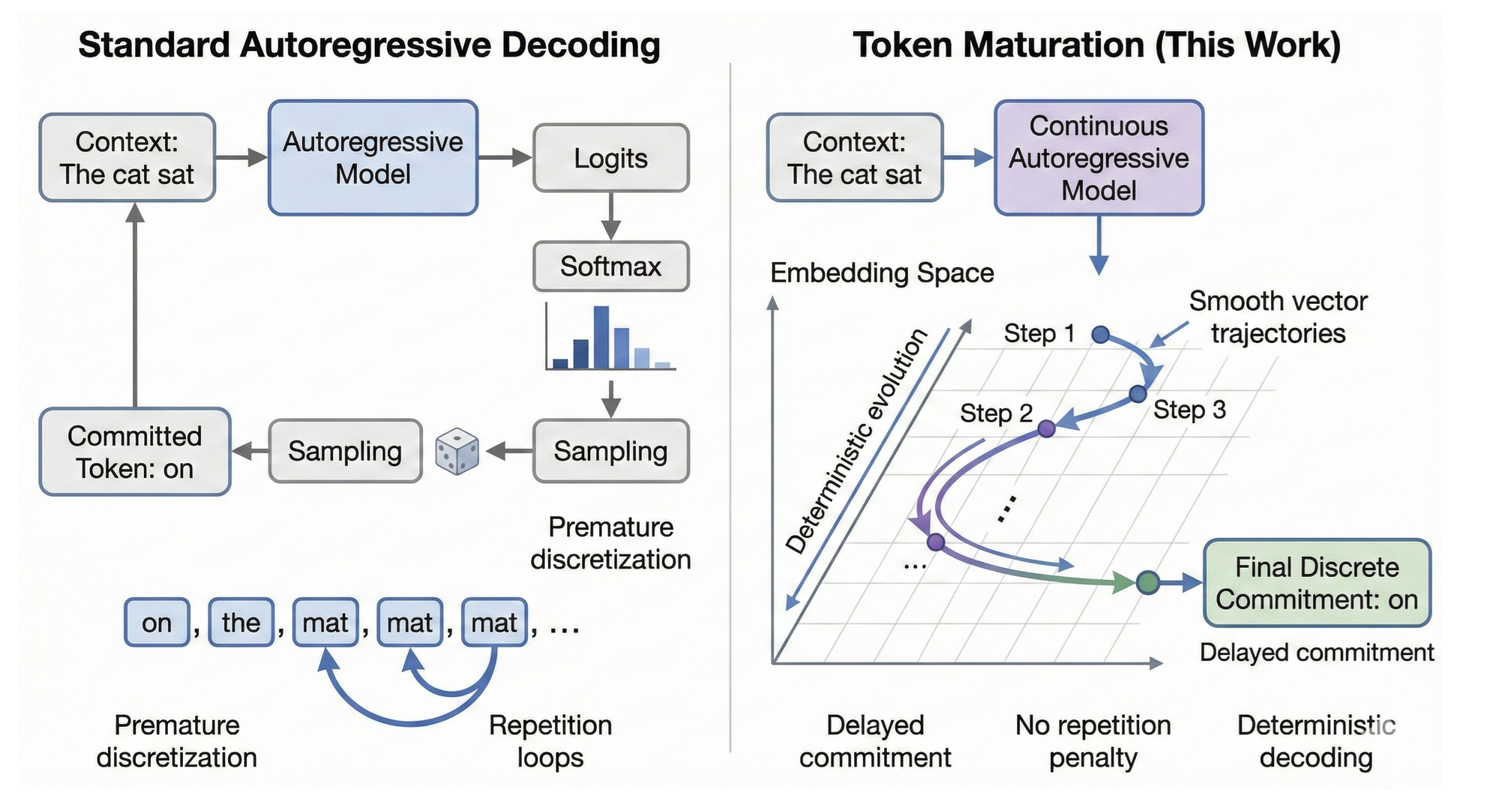
Standard autoregressive LLMs commit to a discrete token at every step—prediction and commitment are fused into a single operation. This forces uncertainty to collapse immediately, leading to degenerate repetition under greedy decoding and dependence on sampling heuristics.
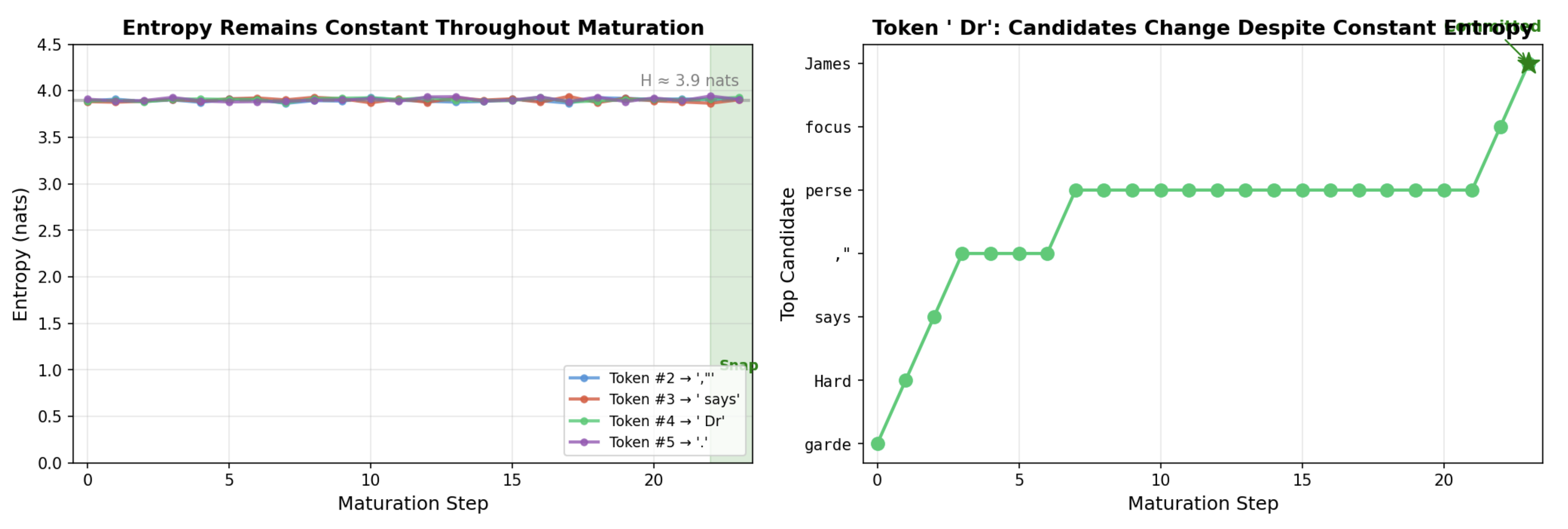
Token Maturation decouples prediction from commitment. The generation state is a sequence of continuous vectors. New tokens emerge through iterative refinement in embedding space, and discrete commitment happens only when vectors geometrically stabilize—not when probability concentrates.
Continuous State
The entire sequence—including already-generated tokens—lives in continuous embedding space. No discrete indices until final projection.
Delayed Commitment
A "liquid tail" of K vectors is iteratively refined. Tokens are committed only when they reach the front of the buffer.
Geometric Stability
Commitment occurs via nearest-neighbor projection when vectors stabilize—even if the induced token distribution remains high-entropy.
Immediate Commitment
Each token is immediately discretized via sampling or argmax. Uncertainty must collapse to a single choice at every step.
Deferred Commitment
Committed tokens (white) followed by a liquid tail (cyan) that matures through continuous refinement before projection.